

You’ve read at least three AI Engineer vs Data Scientist comparison articles before landing here. You know the salary ranges. You’ve seen the skill lists. You’ve probably made a Notion doc with pros and cons that you haven’t opened in two weeks.
And you’re still in the same place.
That’s not an information problem. That’s an orientation problem. You have enough data to build a case for either side, which means the data isn’t helping anymore. So let’s stop pretending it will.
Why This Decision Feels Stuck
Here’s what’s actually happening for most people reading this.
You’re not a fresh graduate weighing two options. You’re someone 2–5 years into a career that’s starting to feel like a treadmill. Maybe you’re a Data Analyst who keeps getting told you’re “almost a Data Scientist.” Maybe you’re a developer who pivoted into ML, built a model or two, and now can’t figure out where that fits. Maybe you’ve been in IT services long enough to know that your current role won’t get you where you want to go; you don’t know which exit to take.
The comparison posts are written for people who haven’t started yet. You have. That’s why they feel useless.
What you actually need to know is: given the specific corner I’m standing in right now, which direction has a shorter real path, not the learning path, the employment path. Those are different.
What Shifted in 2026, Specifically
In 2023, every company wanted to “explore AI.” They hired Data Scientists to run experiments, build dashboards, and show the leadership team what was possible. A lot of that work was proof-of-concept stuff that never shipped.
That phase is mostly over.
Companies have spent two years and serious money on AI experiments. Boards are asking what was shipped, not what was explored. That pressure has completely changed what gets hired for. The question isn’t “can you build a model” anymore. It’s “Can you keep one running in production without it quietly failing every third week?”
The Data Science job market didn’t collapse, but it bifurcated. There are roles for people with deep domain expertise who can extract real business value from data. And there are roles for people who can build and maintain AI systems in production. The middle generalist ML, moderate coding skills, decent statistics, that’s the layer that’s been squeezed hardest.
If you’re sitting in that middle layer right now, you’re probably feeling it. The applications are going unanswered. The rejections that don’t explain themselves. The job descriptions list 12 skills, and you have 9 of them, and somehow that’s not enough.
That’s not bad luck. That’s the market telling you the middle is crowded, and both exits require you to go further in one direction.
How LLMs Quietly Reorganized Both Roles
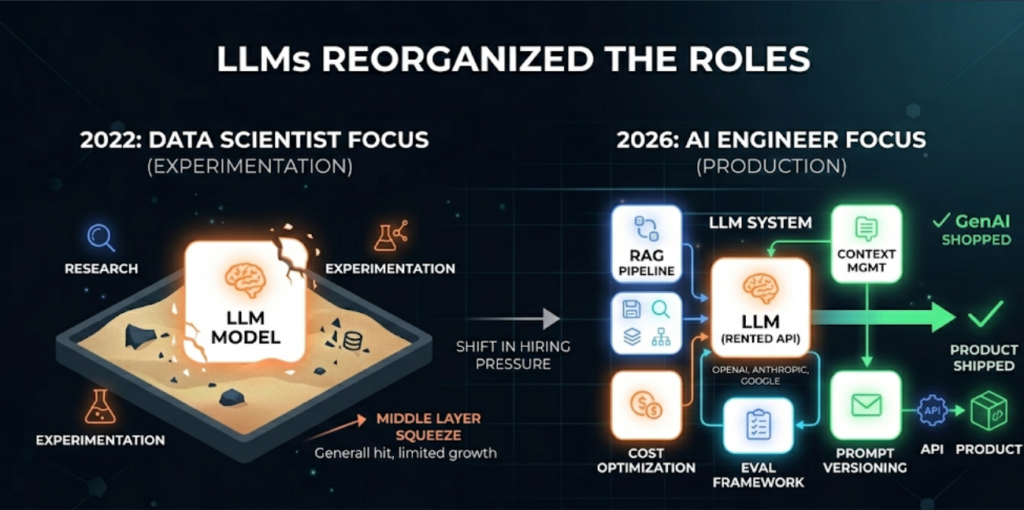
When ChatGPT landed in late 2022, a lot of Data Scientists thought it would create more work for them. In some ways, it did. In more ways, it restructured the work in a direction they didn’t expect.
Most companies building AI products in 2026 are not training models. They’re renting intelligence from OpenAI, Anthropic, Google, or an open-source equivalent, and then building systems around it. That means the job isn’t “build a model that predicts X.” It’s “wire this API into our product, make it fast, make it reliable, make it not hallucinate on customer data, and figure out what to do when it does.”
That is an engineering problem. Specifically, it involves RAG pipelines, context management, inference cost optimization, evaluation frameworks, and prompt versioning. None of those things appear in a standard Data Science curriculum.
Data Scientists still have work evaluating output quality, thinking through what the model should and shouldn’t be trusted to do, and managing fine-tuning datasets. But that’s a supporting role in most companies, not the lead role. The person who owns the GenAI product end-to-end is usually an engineer.
When you see a job posting for “GenAI Engineer” or “LLM Engineer” offering ₹30–50 LPA, that role isn’t looking for someone who has read papers about transformers. It wants someone who has debugged a RAG pipeline at 11 pm because retrieval quality dropped, and nobody knows why. Specific, messy, production reality. That’s the actual job.
If you’re serious about building real-world GenAI applications, read AI Engineering: Building Applications with Foundation Models by Chip Huyen it focuses on deploying and scaling foundation model systems.
AI Engineer vs Data Scientist Salary: Without the Optimistic Framing
| Role | Entry Level | Mid – Level (Product/AI-Driven) | Senior |
|---|---|---|---|
| AI Engineer | ₹8–15 LPA | ₹25–40 LPA | ₹50–80 LPA+ |
| Data Scientist | ₹6–12 LPA | ₹18–28 LPA | ₹35–60 LPA |
| Role | Entry Level | Mid – Level (Product/AI-Driven) | Senior |
|---|---|---|---|
| AI Engineer | $100K–$130K | $140K–$180K | $200K+ |
| Data Scientist | $95K–$120K | $120K–$155K | $175K+ |
Those numbers are real. Here’s the part that usually gets left out.
The ₹25–40 LPA mid-level AI Engineer role exists at maybe 200–300 companies in India. Seriously funded startups, Indian product companies, MNC R&D centers, and a few consulting firms doing real AI work. That’s it. The rest of the 2,000+ companies that have “AI Engineer” in their job listings are mostly offering ₹10–18 LPA for work that involves maintaining someone else’s pipeline or writing Python scripts around a third-party API.
Same story for Data Science. The ₹20–28 LPA Data Scientist role at a good company is real. But the path there runs through either strong domain expertise (you understand the business problem deeply, not just the data) or a portfolio of work that shows genuine impact, not accuracy metrics on a Kaggle dataset, but something like “I built a churn model that the retention team actually used, and it changed how they allocated budget.”
Most people are applying to the aspirational tier before they’ve built the credentials for it. Then they blame the job market. The job market isn’t wrong; the positioning is.
Who Should Choose What
No quiz. No “find your personality type.” Just the honest filters.
Choose AI Engineering if…
- You’ve already built something with an API, a queue, a database, or a server, even outside of ML, and that kind of work didn’t feel like punishment
- When something breaks in a system, your first instinct is to dig in, not hand it off
- You can read a Docker error message, feel mildly annoyed, and then fix it rather than feel personally attacked
- You’re okay with your work being invisible when it’s working correctly, because “the model ran without issues this week” is the actual success state
- You want the salary ceiling that comes with infrastructure ownership, and you understand the on-call stress that comes with it
Choose Data Science if…
- You have real industry knowledge, you’ve worked in banking, pharma, logistics, and retail, and you understand how decisions actually get made in those environments
- You’re the person in a meeting who notices that the framing of the problem is wrong before anyone else does
- You find the communication layer interesting, turning analysis into decisions, not just reports
- You want a career where being deeply right about something matters, not just being fast at deploying something
- You’re mid-career, you have domain depth, and you want to add data skills to what you already know rather than restart from zero
The Entry Question Nobody Answers Honestly
Data Science is easier to enter. That’s true. There are more courses, clearer beginner paths, and lower technical requirements at the junior level.
But here’s what that actually means in 2026: the entry-level Data Science market in India is brutally crowded. Thousands of people with the same resume, 3 Coursera certifications, a house price prediction project, a customer churn project, maybe a sentiment analysis thrown in. All are applying to the same 50 openings at decent companies.
The companies that are still hiring junior Data Scientists without domain experience are mostly doing so at ₹6–10 LPA for work that is closer to data cleaning and report generation than actual modeling. That’s not a bad starting point, but it’s worth knowing that’s what “easy entry” often means in practice.
The AI Engineering entry is harder. You need Python that actually works in a production context, not just Jupyter notebooks. You need to understand what happens between “model trained” and “model serving requests.” You need to have thought about failure modes. That’s a higher bar.
But the reward for clearing that bar is thinner competition. A fresher with a deployed FastAPI endpoint, a working vector search implementation, and a clear explanation of what broke and how they fixed it, that person is genuinely rare. Not because the technology is impossible to learn, but because most people stop at the tutorial stage.
The honest summary: Data Science has an easier entry and harder growth. AI Engineering has a harder entry and cleaner growth once you’re in.
Switching from Data Science to AI Engineering
If you’ve been working as a Data Scientist for 2–4 years and you’re thinking about this switch, here’s the realistic picture.
Your existing skills are more transferable than most job descriptions make them seem. Python, you have. Statistical intuition, you have. Understanding of how models learn and where they fail, you have. What you’re missing is the operational layer, how models live and behave after they’ve been trained.
The specific gap looks like this: you know how to train a model. You probably don’t know how to serve it under load, version it properly, detect when it’s degrading without someone telling you, or roll it back cleanly when something goes wrong. That’s what needs to be built.
Concrete things to learn, in order of priority:
First, FastAPI or Flask builds a real model serving endpoint, not a demo. Actually, call it from another script, handle errors, and log requests.
Second, Docker containerizes that endpoint. Understand why this matters when someone else needs to run your code.
Third, basic MLflow or equivalent, track your experiments, version your models, and understand what “model registry” means in practice.
Fourth, one cloud provider at a basic level, not certification level, or deployment level. Deploy something on AWS or GCP that actually runs.
Fifth, monitoring adds basic logging to your endpoint. Know when it’s slow. Know when predictions are shifting.
That’s it. Not ten things. Five things, done for real, with one project that ties them together. Something that broke, that you debugged, that you can explain in detail in an interview.
Six to nine months of consistent work. Not full-time study, consistent work after hours. That gets a mid-level Data Scientist to a credible AI Engineering interview.
One honest note: a few people discover midway through this process that they actually hate operational work. The debugging, the infrastructure, and the “why is this container behaving differently in production” questions. If that happens to you, it’s useful information. Don’t ignore it.
Want to build ML systems that actually run in production?
Designing Machine Learning Systems by Chip Huyen is a practical book that explains real-world deployment and scalable ML architecture.
What Interviews Actually Test in Reality
This is the part most guides skip. Not the syllabus, the conversation.
AI Engineering interviews are trying to find out one specific thing: have you actually shipped something, or have you only studied how to?
The questions usually sound like this:
- Take me through a model you deployed end-to-end. Not the training part, the part after that.
- Latency in your API doubled overnight. Walk me through how you debug that.
- How do you know when a model in production is drifting? What signals are you looking at?
- What does your Docker setup look like for a model serving project?
- Tell me about something that broke in a project. Not generally specifically. What was the error? What did you try first? What actually fixed it?
If you’ve only done tutorials and Kaggle projects, these questions will expose that fast. The interviewer isn’t trying to be difficult; they’re trying to figure out if you’ve felt the pain of production, because that pain is what the job involves daily.
Data Science interviews test a different kind of readiness. They want to see how you think, not just what you know.
The questions usually sound like this:
- Here’s a business situation with incomplete information. How do you approach it?
- You built a model with 87% accuracy. The business team isn’t happy. Why might that be, and what do you do?
- How would you explain the tradeoff between precision and recall to a non-technical product manager?
- Design an A/B test for this feature. What could go wrong with your design?
- Walk me through how a result from your analysis actually changed something, a decision, a process, a budget.
The failure mode here isn’t technical ignorance. It’s being technically correct, but unable to connect it to anything a business cares about. A lot of strong ML students fail Data Science interviews because they answer everything in model terms and none of it in decision terms.
Two different failure modes. Know which one you’re more likely to hit and prepare for that one specifically.
What “Future-Proof” Actually Means Here
Future-proof is a term people use when they’re scared of backing the wrong horse. Understandable. Also, slightly the wrong question.
AI Engineering stays relevant as long as you keep the technical layer current. That means genuinely re-learning tools every 18–24 months. Not skimming a tutorial, actually rebuilding your working knowledge from a different foundation. MLflow was the standard a year ago; parts of that workflow are already being replaced. FastAPI patterns are shifting. The LLM serving layer is being rewritten constantly. If you find that kind of churn energizing, AI Engineering will reward you. If it sounds exhausting, that’s important information.
Data Science future-proofing works the opposite way. The more specific your expertise, the safer you are. A Data Scientist who genuinely understands how credit risk models interact with RBI regulatory requirements, or how clinical trial data quality affects FDA submissions, or how demand forecasting failures cascade through a retail supply chain, that person is not being replaced by an AI dashboard. The model might change. The domain expertise that tells you whether the model’s output makes sense doesn’t get replaced.
Generalist Data Science, good at everything, specialized in nothing, is the lane under the most pressure. Not from AI directly, but from the increasing number of people competing for the same undifferentiated roles.
The Mistake That Keeps Repeating
Every few months, someone in a career advice forum asks: “I’m a Data Scientist with 3 years of experience, should I become an AI Engineer for better pay?”
Ninety percent of the answers say yes. Higher salary, more demand, better future.
What those answers don’t ask: what does this person’s day actually look like when the switch is complete?
Because here’s the reality. AI Engineering, at most companies, involves a significant amount of work that has nothing to do with AI. Infrastructure configuration. Environment debugging. Dependency conflicts. Pipeline maintenance. Documentation that nobody reads until something breaks. On-call rotations where the emergency is a misconfigured container, not an interesting model failure.
If that kind of work genuinely interests you, if systems problems feel like puzzles rather than obstacles, AI Engineering is right for you. The salary premium is real, and the work can be deeply satisfying.
If you’re eyeing AI Engineering primarily because of the salary and the title, and you’ve never actually enjoyed infrastructure work, you will find yourself in a well-paying job that slowly drains you. That’s not a catastrophe, but it’s worth knowing before you spend a year upskilling for it.
Same trap runs the other way. Some developers push themselves toward Data Science because it sounds more intellectual, more analytical, more like the interesting parts of their job. They get there and discover that a significant portion of Data Science work is stakeholder management, explaining the same concept six different ways until it lands, and building reports that answer questions that will be replaced by different questions next quarter.
Pick based on which difficult parts you can tolerate. The exciting parts of both roles are roughly equal. The difficult parts are very different.
Where to Start If You’re Mid-Career and Already Tired
Stop looking for the perfect roadmap. There isn’t one that accounts for where you specifically are.
Instead, do this first: make a list of everything you’ve actually shipped. Not topics you’ve studied. Not projects you started. Things that ran somewhere and someone used. Keep the list honest. If it’s short, that’s your real problem, not your skill gaps, your output gaps. You can’t interview your way into a good role without work to point at.
Once you have that list, identify which gap is smaller for you:
The engineering gap you struggle with is systems, deployment, and making things run reliably outside your laptop. If this is smaller, AI Engineering is reachable faster.
Domain/communication gap you struggle with: ambiguous business problems, stakeholder communication, and connecting technical work to decisions. If this is smaller, deepening in Data Science makes more sense.
Most people reading this already have a sense of which gap is smaller. They’re hoping the article will tell them the other option is also fine, so they don’t have to do the harder work of closing a gap they’ve been avoiding.
It’s not fine. But the gap you’ve been avoiding is also probably not as large as it feels.
Frequently Asked Questions
Is AI Engineering better than Data Science in 2026?
For most people entering or switching now, AI Engineering has a stronger market pull. Companies that spent 2023–2024 experimenting are now hiring to deploy, and that’s engineering work. Data Science remains strong in companies where domain expertise drives business decisions, such as finance, healthcare, and logistics. “Better” depends on what you’re starting from and what kind of work you can sustain. In pure market terms, AI Engineering has the edge right now. In career sustainability terms, the answer depends on you.
Which pays more in India AI Engineer or a Data Scientist?
At the entry level in IT services companies, both pay similarly, ₹8–14 LPA, with little meaningful difference. The gap appears at product companies and funded startups. Mid-level AI Engineers there typically earn ₹25–40 LPA. Data Scientists in the same environment earn ₹18–28 LPA. The title doesn’t create the gap. The company type and the reality of what you’re building do. A senior Data Scientist at a fintech product company often earns more than a junior AI Engineer at a services firm.
Can a Data Scientist switch to AI Engineering?
Yes, and it’s one of the more realistic transitions in tech right now. The conceptual foundation of Python, ML understanding, and statistical thinking transfers directly. What needs to be added is operational: model serving, MLOps basics, Docker, cloud deployment, and production monitoring. One real end-to-end deployment project, where something broke, and you fixed it, does more for interview credibility than six months of courses. Realistic timeline for a mid-level Data Scientist: six to nine months of focused work.
Is Data Science saturated in 2026?
The generalist entry-level layer is genuinely saturated. Candidates with similar portfolios, similar projects, and similar certification lists are competing for the same junior roles at decent companies. The saturation thins fast once real domain expertise enters the picture. A Data Scientist who understands pharmaceutical regulatory requirements, or agricultural commodity pricing, or insurance underwriting, that combination is not saturated. The market is full of people who know ML. It’s less full of people who know ML and something else deeply.
How has Generative AI changed hiring?
Most companies are building on top of foundation models, not training their own. That shifted hiring toward engineers who can deploy LLM systems reliably, RAG pipelines, inference optimization, API integration, and evaluation frameworks. Data Scientists still contribute through output quality measurement and fine-tuning dataset work, but that’s a supporting function in most organizations. The lead technical role in GenAI products is almost always an engineer. Most “GenAI” job postings with high salaries are infrastructure roles with an exciting label.
Which is easier to learn?
Data Science has a lower initial barrier, more courses, clearer learning paths, faster route to a first job. AI Engineering requires systems thinking and deployment experience earlier in the journey. That said, the lower barrier in Data Science means higher competition at the entry level. Easier to start does not mean easier to build a career in. The more useful question is which one has a learning curve that matches how your brain works, not which one has more YouTube tutorials.
Which has better long-term salary growth in India?
AI Engineering has a steeper ceiling, but almost entirely at product companies and AI-first startups. At services companies, growth plateaus for both roles at roughly the same points. The variable that matters most for long-term salary in either field isn’t the job title; it’s whether the company treats AI as its core product or as a support function. Being an AI Engineer at a company where AI is the product is worth three times more, long-term, than being an AI Engineer at a company that has an “AI team” as a cost center.
The comparison posts will keep telling you AI Engineering pays more, and Data Science is easier to enter, and both of those things will remain technically true and practically incomplete.
What they won’t tell you is that most of your career happens in the ordinary hours, not the breakthrough moments. The Tuesday afternoon when you’re debugging a pipeline that should work and doesn’t. The Thursday when you’re explaining why the model’s recommendation was wrong to a business team that trusted it. The Sunday when something broke in production, and it’s yours to fix.
Your choice is really a choice about which of those ordinary hours you can inhabit without losing yourself.
The salary follows competence. Competence follows showing up. Showing up is only possible when the work doesn’t hollow you out.
Pick the role whose hard days feel like problems worth solving. Everything else is noise.
Related Posts 📌
AI Engineer vs AI Automation in 2026: Same Field, Opposite Burnout Paths